I attended 2022 MLSys Conference and I wanted to share some learnings from the conference.
Collaboration of ML and Industry The Future of MLSys: Industry and Academia Panel
A lot of the papers at MLSys this year were from co-contributors who came from both industries and academic institutions. The panel answered a lot of questions on the difference between working on ML Research in Academia and Companies, and on deciding between the two. They argued largely though for more fusion between the two. Companies typically have more funds to spend on compute but a lot more rigidity on the problems they focus on solving, whereas academia have less funding and more freedom to explore. More collaborations where academic researchers have access to compute and resources and where industry researchers have access to more ideas will drive ML progress.
Accelerating Engineering with Machine Learning
Ryan Adams, a professor at Princeton University had a great talk about the possibilities of using ML in mechanical engineering: CAD, Design, Simulation, fabrication, control. In his opinion, mechanical engineering has been overlook even though there is a large number of inefficiencies and errors that occur in the space which cost companies millions. Machine learning can be applied to CAD to predict constraints, or provide autocomplete for CAD designers. There are also other applications to computational physics, PDE solving, and computer numerical control.
Adams shared that hard problems in traditional engineering can improve ML itself and could be the key for embodied intelligence. This is similar to the case of Jax, Autograd which came from trying to solve problems in molecular biology space.
He also reminded us that not every problem has to be solved with deep learning.
INTERESTING ML IN SYSTEMS PAPERS:
- Online Datacenter Straggler Prediction paper
- Data Drift Mitigation in Machine Learning for Large-Scale Systems paper
Dave Patterson on Efficient Computation, Optimizations and Sustainable AI
Dave Patterson shared some ideas about how far computation efficiency has come in terms of hardware and also software efficiency improvements and why he’s optimistic about how far these improvements have gone towards improving carbon emissions due to ML computations. He also shared some ideas about directions to consider to improve ML efficiency even further. Deep neural network(DNN) models are getting larger: e.g. GPT 2 - 1.5B parameters → GPT3 - 175B parameters, AlexNet(2013) - about 0.0001 petaflop/s-day vs AlphaGo Zero(2018) - ~10000 petaflop/s-day (300,000x increase) ** Petaflop/s-day is the total number of compute operations if you had a computer with throughput 1 PetaFLOP/s working on a problem for a full day He advocated for making optimizations to both compiler and hardware to improve performance and maintain/improve DNN quality. Also for making changes to DNNs themselves and using auto-ml to pareto-optimize ML model performance and quality on ML accelerators and using ML to improve ML performance. Other notable points:
- Focus on reducing memory accesses instead of reducing FLOPs.It’s easy to scale up flops by adding ALUs to balance energy of memory accesses.
- Use high-bandwidth memory(HBM) to allow fast switching between tenancy since inference needs multi-tenancy.
- Maintain compiler optimizations and compatibility.
Carbon Emissions
Patterson shared some of the more malthusian predictions about carbon emissions from ML workloads, such as some predicting that by 2024 ML models’ environmental cost would be roughly as much as New York city. He shares why some of this thinking is faulty and why TPUs (which he called the most influential computing since RISC) helps resolve these.
- Largely hard to measure tCO2e (tonnes of carbon dioxide equivalent)
- Two types of emissions:
- Operational emissions (operating hardware/datacenters)
- Lifecycle (manufacture of chips, datacenters). Largely harder to measure lifecycle emissions
- Carbon emissions can be improved by reducing energy with:
- Bettermodels (4xenergyimprovement)
- Machines P100 GPU vs TPU (14x energy improvement)
- Mechanization (datacenter efficiency)
- Geographic locations, e.g.cloud data centers in Oklahoma with wind use less energy than otherlocations
An example of all these working together is GLAM which has better carbon efficiency than GPT-3 and about the same performance, achieved by using TPUs and datacenters in places like Oklahoma.
- 7x parameters as GPT-3 but 3X less energy and 14x less CO2e
Researchers should also be encouraged to put carbon costs for models in their papers. More info on improving energy efficiency

Privacy-Preserving ML
Improving efficiency of Federated Learning (FL)
- Achieving synchronous and asynchronous FL at scale paper
- Async FL is faster and more efficient than sync FL
- Works with differential privacy
- A more efficient and less complex algorithm for preserving privacy of users in Mobile FL when recomputing for dropped users. slides
Towards Building a Responsible Data Economy
Dawn Song shared a framework for responsible data use. She shared challenges with data privacy: tension between utility and privacy, data is non-rival (can be copied), data relationships (data about one entity can reveal information about other entities), and why traditional solutions are inefficient: data encryption only protects data at rest, anonymizing data doesn’t necessarily protect privacy. Data protection in use needs:
- Control use of data without copying raw data→secure computing hardware(Trusted Hardware,Secure multiparty computation (SMPC), Fully homomorphic encryption (FHE) keep data in use by applications confidential); federated learning - data never has to leave owners machine
- Protect computation inputs from leaking sensitive information→differential privacy-computation output won’t leak sensitive information
- Enforce data use policy→distributed ledger-provides immutable log to ensure data usage is compliant
Song shared some projects on differential privacy - chorus, which rewrites sql queries to private queries and Duet, a type system for enforcing differential privacy. She also shared a project, CoLearn - an open source platform helping bridge the gap between crypto protocol design and real world deployment.
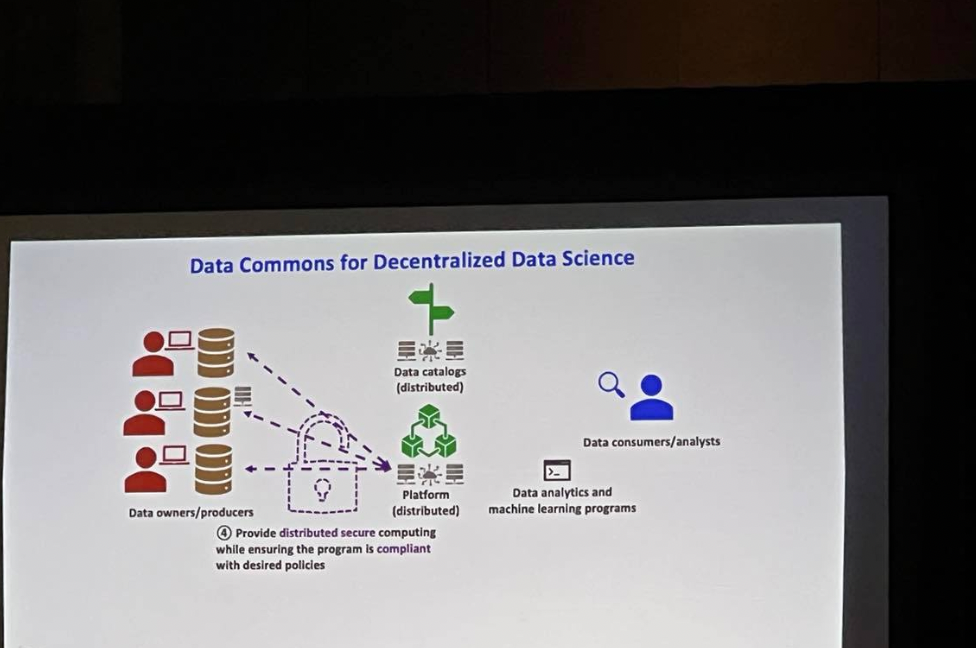
 She talked about decentralized data science where data owners register their data with policy specified on a distributed third-party platform, and data consumers can consume data respecting the policies. An example use case would be conducting medical research using federated learning and gaining insights from multiple medical institutions.
She talked about decentralized data science where data owners register their data with policy specified on a distributed third-party platform, and data consumers can consume data respecting the policies. An example use case would be conducting medical research using federated learning and gaining insights from multiple medical institutions.
Song also generally shares a vision for a data economy where data contributors own and are paid for their data and data trusts/commons enable this and data trustees will manage and protect users data. This will enable a new type of data asset, a capsule of data and policies that can be consumed along specific guidelines for a specific fee or exchange value. This will use blockchain for logging and enforcement of usage policies and privacy computing which ensures that data remains private during compute.
Model Efficiency Improvements:
- Improving efficiency for Graph neural networks
(GNNs): paper
- GNN frameworks (think graph data structure plus neural networks) are based on a message passing paradigm, and express GNN models using built-in primitives and user-defined functions (UDFs).
- GNNs differ from DNNs
- DNN: tensor computation using operators to transform tensors
- GNN: graph computation using message passing: edge(how to send a message), node(how to use a message)
- This paper was about improving UDFsw hich are low performant, high memory using a compiler for GNNs.Uses broadcast reordering and fusion to eliminate intermediate data materialization to achieve optimizations.
- Torch Sparse for point cloud inference: paper
- Pointcloud inference is used for AR/VR, self-driving cars since it provides real-time,low latency inference
- Point cloud inference usesS parse convolution (as opposed to conventional convolution). However, sparse convolution has poor performance on GPUs since sparsity and irregularity make mapping and data movement difficult.
- TorchSparse has similar interface to PyTorch and
- improves adaptive grouping for matrix multiplication
- optimizes data movement with locality-aware memory
ML Compilers
There was a whole track/symposium about improving ML compilers and this seems like a big direction for ML in general, since deep learning compilers make it easier to support heterogenous hardware without ML frameworks having to individually support all hardware platforms.
- See Dave Patterson’s talk shared above.
- Presentation on TinyML under 256kb of memory. This showed achieving on-device training using a tinyML compiler engine and optimizations. There was also a pretty cool demonstration of this training working live on a arduino-type device
- The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding.
- This paper was about having a more efficient way to generate code for ragged tensor (tensors with dimensions of varying length) operators since padding ragged tensor is largely inefficient using fused loop extents an iteration variable relationships as well as lowering memory access with memory offsets.
- Also generally cool projects on ML compilers and automated discovery of ML optimizations from the Catalyst group at CMU
Other Interesting Papers:
Pathways Asynchronous Distributed Dataflow for ML (one of the best paper awards)
- Pathways is asingle-controller, asynchronous distributed dataflow system for distributed ML workflows
- The talk starts by classifying distributed systems into:
- First-wave single-controller model where user code is in one process and the process delegates to multiple worker via distributed system, e.g. MapReduce, Spark, TensorFlow.
- Second-wave multi-controller modelw here user code is copied in every process and runs in lock-step,e.g. PyTorch, JAX.
- The paper proposes a third-wave of a system like PathWays which does single controller with single program, multiple data (SPMD) execution.
- The goal is to move away from second-wave, since decoupling user process from the accelerator allows for resource virtualization and flexible programming.
- Problem with first-wave:
- Scalability: single process controller does not scale with the number of accelerators→can be solved with careful design and remote execution.
- Latency: single controller has datacenter network rather than directly interfacing with hardware. Solve latency by taking a distributed graph: DAG nodes (computation) and edges (data transfer), and, instead of performing computation, enqueue operations as input and send to the next node.
- Since accelerators are fast, enqueue starts to match compute time
- Typical ML workload has very little data-dependent control flow (mostly linear algebra operations),so we can run most operations while enqueueing others.