Machine Learning Compilers
I’ve been reading about Machine Learning Compilers and wanted to share some notes. I read this paper “The Deep Learning Compiler: A Comprehensive Survey” and summarized some key takeaways.
Outline
- Background
- Intro to DL Compilers
- Deep Learning Compiler Architecture
- High-Level IR
- Low Level IR
Background - Deep Learning
Neural Networks of multiple layers are being used in natural language processing, computer vision, etc to solve problems like machine translation, recommendations, self-driving, etc. There have also been many deep learning frameworks aiming to simplify building neural networks e.g. mxnet, Microsoft Cognitive Toolkit, Tensorflow, PyTorch, etc.

Neural networks run on different hardware including: General purpose hardware, Dedicated hardware fully customized for DL models, and, Neuromorphic hardware inspired by biological brains.
They also run on different memory architectures (CPU, GPU, TPU) with different compute primitives scalar (CPU), vector (GPU), tensor (TPU)
Since there are different hardware, memory architectures a Neural network can run on, it’s non-trivial for frameworks to add support for all of these hardware, memory architecture.
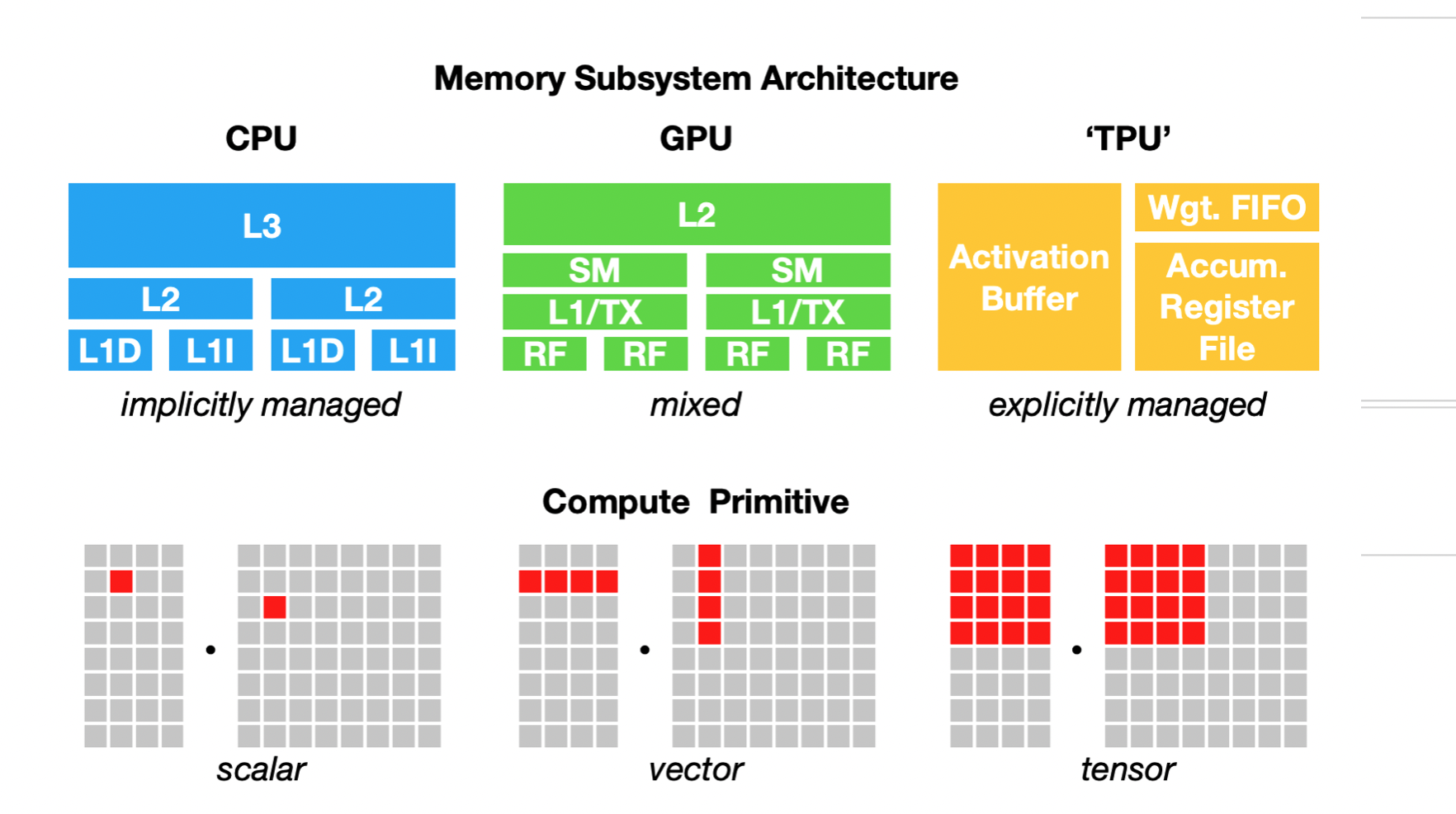
This is where the deep learning compiler comes in.
Deep Learning Compilers
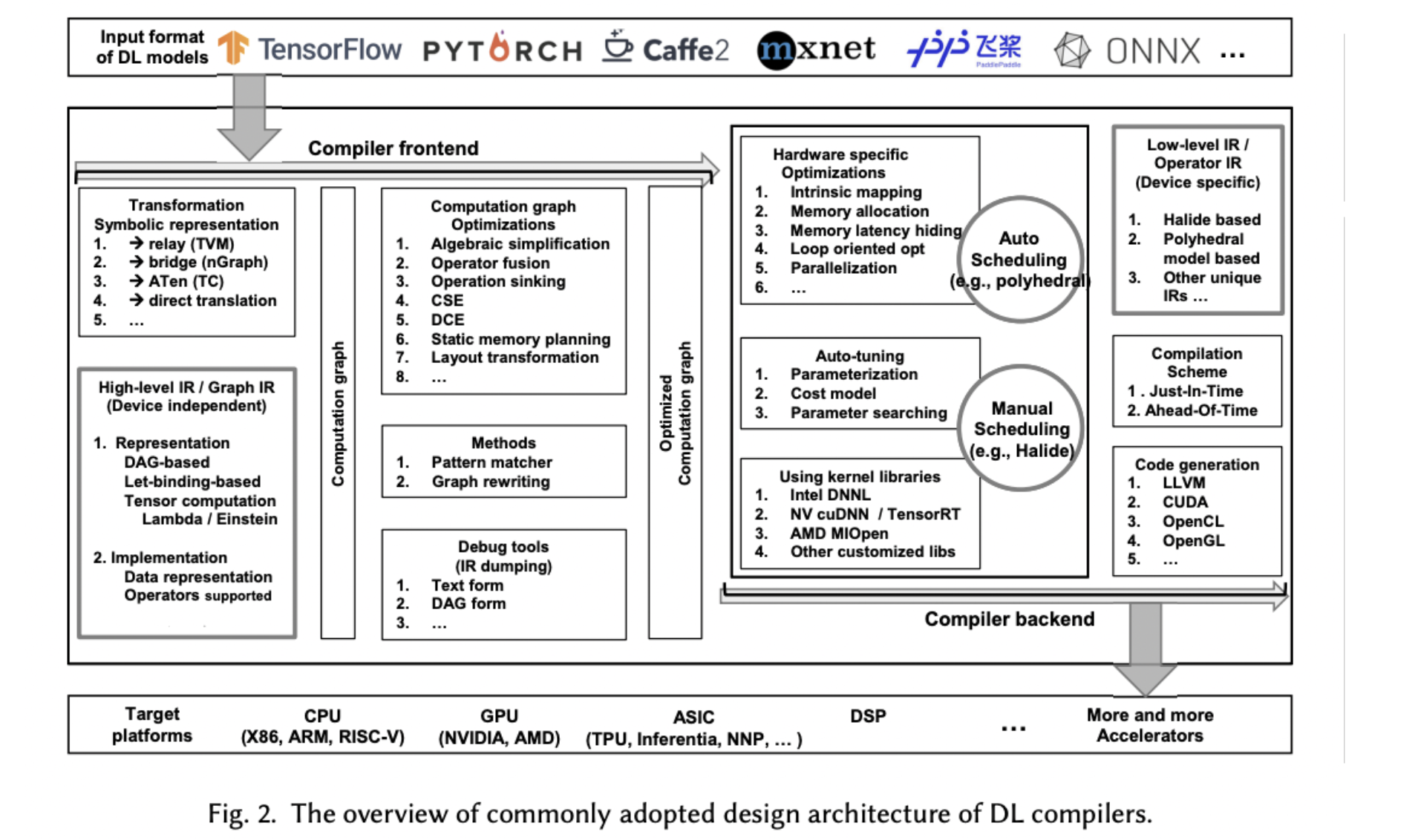
Deep learning compilers solve the problem of supporting different hardware devices and memory architecture for DL libraries. These compilers take in a model definition and return its code implementation on various hardware. With these compilers, we can optimize to model specification and hardware architecture, as well as, incorporate DL-specific optimizations e.g. layer and operator fusion.
Some of the current machine learning compilers are shown below.
| LLVM-Based | MLIR-Based |
|---|---|
| TVM | ONNX |
| Pytorch Glow | Tiny IREE (embedded) |
| XLA | |
| Tensor Comprehensions (TC) | |
| Intel nGraph |
Deep Learning Compiler Architecture
Deep learning compilers typically accept a deep learning model as input, and have two components:
- Frontend, which converts DL model into High-Level Intermediate Representaion (IR)
- Backend, which converts High-Level IR into Low-Level IR
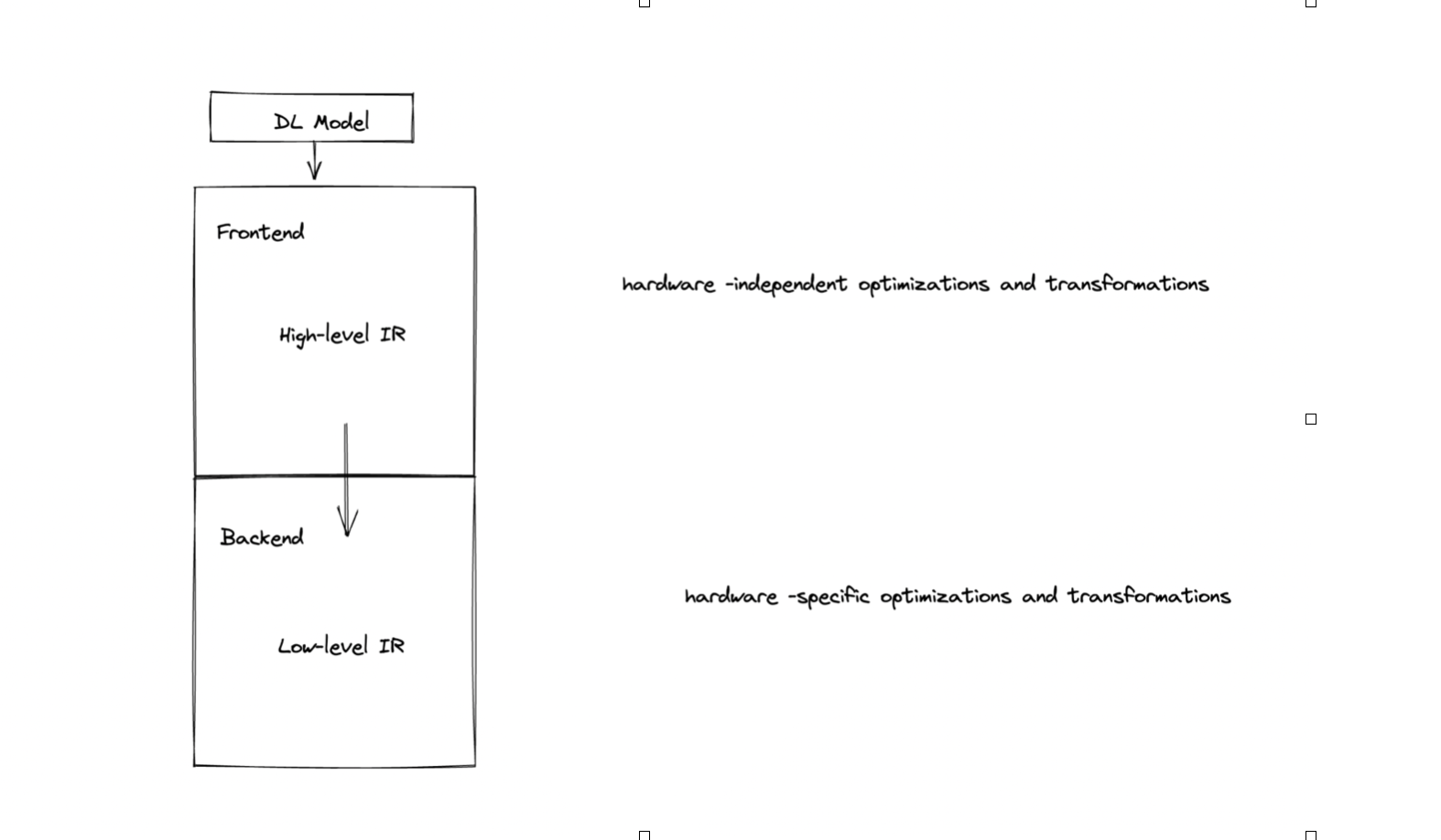
Deep learning Compiler - Frontend High Level IR
There are two general implementations for Deep learning compiler fronends. They can either be:
- Directed Acyclic Graph (DAG)-based
- Here, the IR is represented as a computation graph with nodes and edges
- Nodes: atomic dl operators e.g. convolution, pooling
- Edges: tensors
- Let-binding based
- Here, the IR is represented as Let expressions with restricted scope
- Let expression generates let node (contains operator and variable)
- A map of let nodes is initially generated, containing dl operators (convolution, pooling, etc), and variable (tensors)
Then there is the problem of how to represent the data (tensors in this case) in the IR, Can be:
- Directly by memory pointers
- Or by using place holder
And how to represent the (tensor) computations:
- Function-based
- Lambda expression
- Einstein notation
Deep learning Compiler - Backend Low Level IR
There are two common implementations for the low level IR of a compiler
- Halide-based IR
- This has separation of computation and schedule.
- Tries various possible schedules and choose the best one
- Boundary of memory restricted to bounded boxes
- Used by TVM
- Polyhedral-based IR
- Uses linear programming to optimize loop based code
- Boundary of memory can be polyhedrons with any shape
- Used by PlaidML (nGraph)
TC uses both halide and polyhedral.
Code generation in deep learning compilers is usually lowered to LLVM IR with some optimizations, such as loop transformation in upper IR of LLVM, or passing information about the hardware target for optimization passes.
There are two types of compilation schemes:
- Just-in-Time (JIT): Here executable code is generated on the fly. Therefore, optimizations can be made with better runtime knowledge.
- Ahead of Time (AOT): Here all executable binaries are generated first and then executed. This has a larger scope of static analysis since all executation information is present.
Deep learning Compiler - Frontend Optimizations
There are some optimizations that can be done at the fronend including node level optimizations (e.g. nop elimination, zero dimension tensor elimination), Block level (algebraic simplification, operator fusion or combining loop nests, operator sinking), dataflow level (common sub expression elimination, dead code elimination, static memory planning, layout transformation).
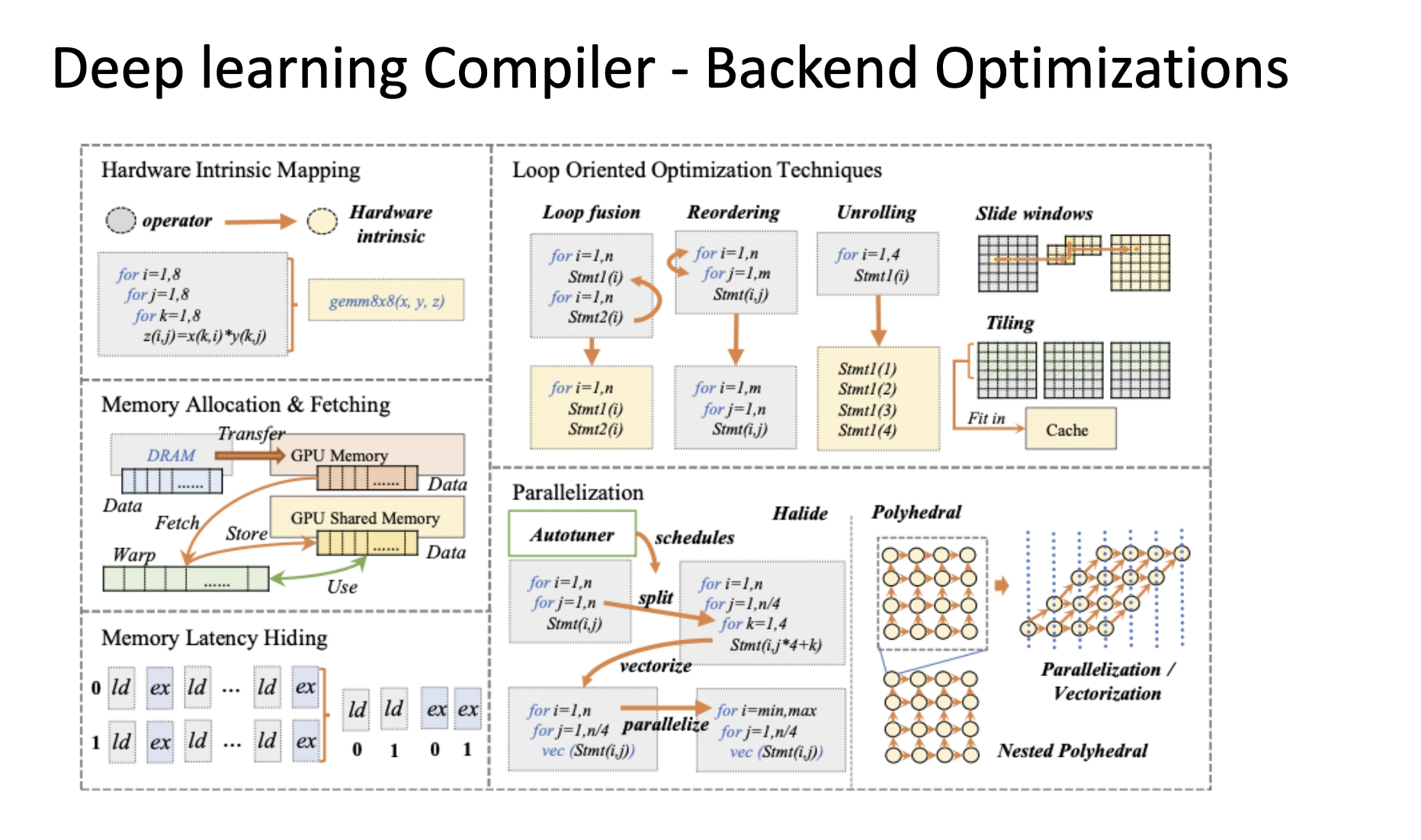
Deep learning Compiler - Backend Optimizations
On the compiler backend, we could do hardware specific optimizations such as Hardware intrinsic mapping, Memory allocation and fetching, Memory latency hiding, Parallelization, or, Loop oriented optimizations (loop fusion, sliding windows (halide), tiling, reordering, unrolling).
It is also possible to use the optimal parameter configuration. There is a large space for parameter tuning, and autotuning helps determine the optimal configuration. Autotuning involves some parameterization, cost model (e.g. black box, ML model), searching technique and acceleration.
Performance Comparison between DL Compilers
From the paper, TVM generally seemed to have the best performance on both CPUs and GPUs
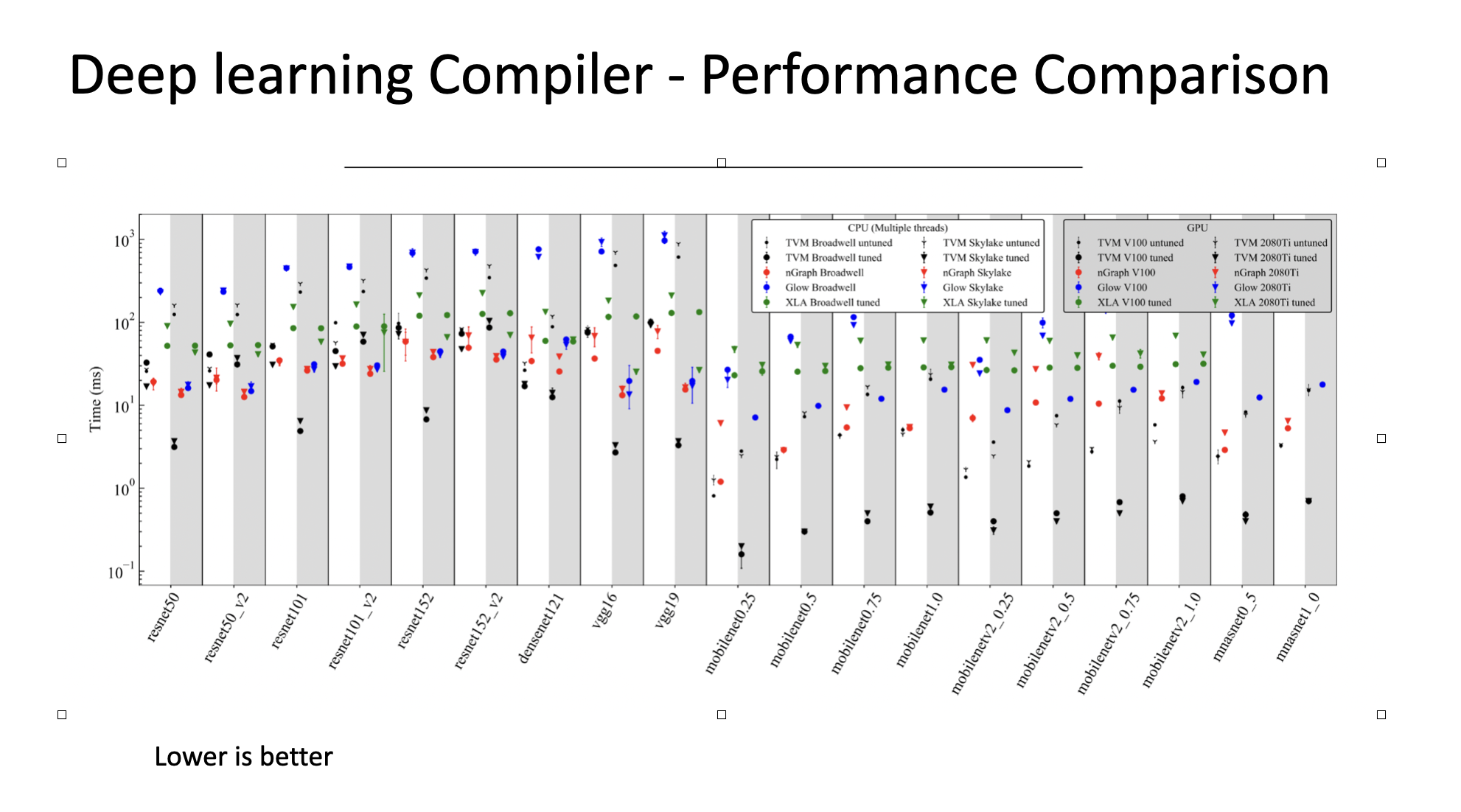
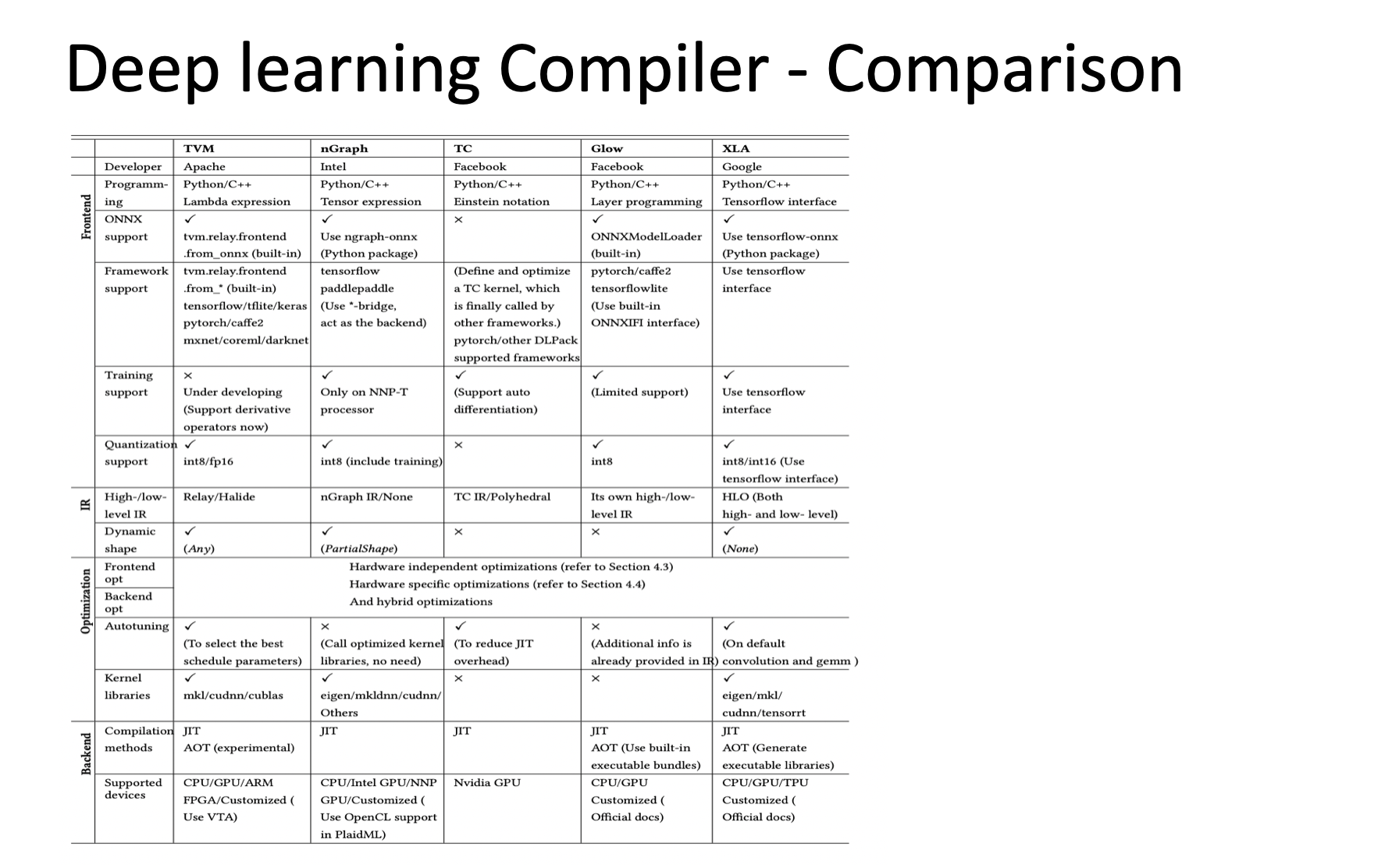
Some Images from The Deep Learning Compiler: A Comprehensive Survey paper
I also found some of Chip Huyen’s thoughts on Machine Learning Compilers pretty insightful: A friendly introduction to machine learning compilers and optimizers blog post